Race the Sun
Race the Sun wouldn’t be Race the Sun without procedural generation.
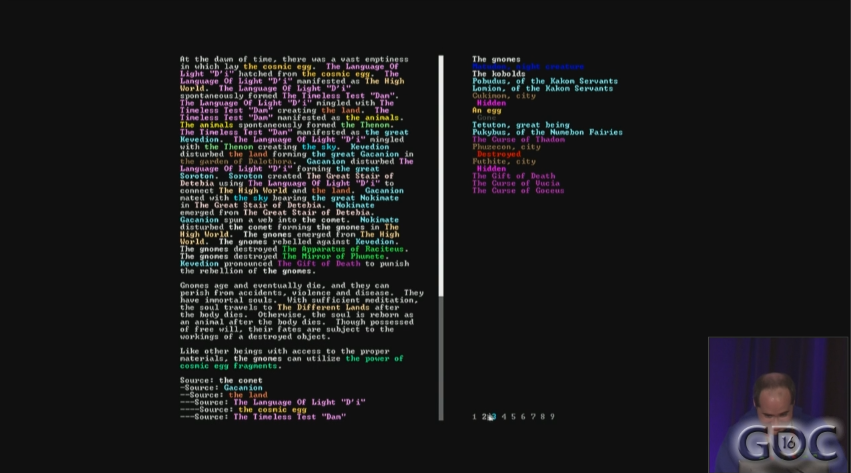
Race the Sun is more or less an infinite runner, only with a 2D plane to maneuver between obstacles and avoid shadows. The twist is that everyone is racing in the same world, which is regenerated every day into a new configuration.
It’s not the only procgen game that’s embraced daily challenges and leaderboards on the same seeded generation (Spelunky and AudioSurf are two other examples). But Race the Sun is built around it.
By giving you a reason to play the same level multiple times, you begin to learn it and develop strategies and relationships. Since the game is all about just-one-more-time runs, these quickly build up to seeing the incidental patterns that would easily be glossed over if every run was a new seed.
One way to make players have a relationship with the things that you generate is to let them have time to develop that relationship. Elite always started the player in the same system, which is why Lave, Leesti, Riedquat, Diso, and Zaonce have thirty years of resonance with players.
Likewise, having the map in Race the Sun persist for a day gives it a sense of ephemerality–you’ll never see this particular configuration again–while also letting you develop a relationship with the emergent space. You’re not just recognizing the building block that places a mountain or tunnel, you’re also also developing a relationship with that particular mountain, and those points that you’ve almost worked out the optimal path to collect without crashing.
Once the player has recognized the building blocks that you’re using to generate your world, it is very difficult to get them to look past that. Race the Sun shows us one way to do it, by persisting the emergent patterns long enough to form an emotional bond with them.