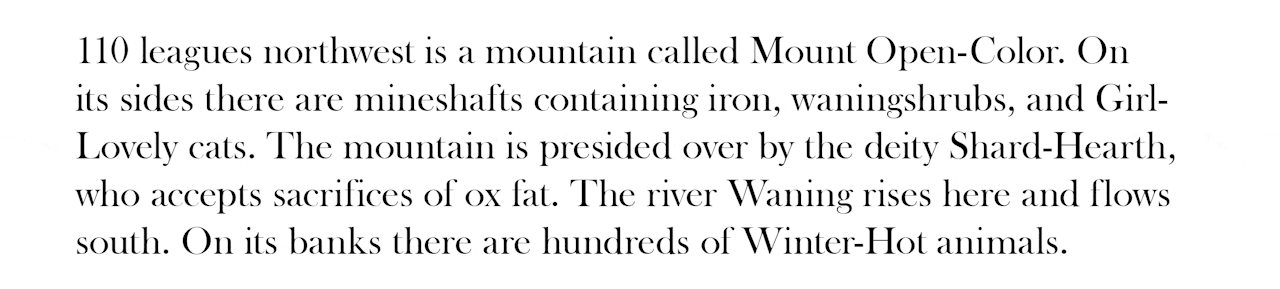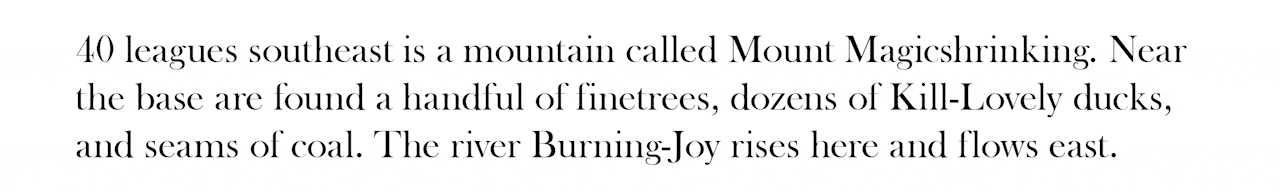Bad News is going to be livestreamed this evening!
So, what is Bad News? It’s a one-player game that takes place in a procedurally-generated town and uses a live actor as an interface. Developed by James Ryan, Adam Summerville, and Ben Samuel at UCSC, it combines generation with improv acting in an innovative intersection between games and theater.
It is inspired by things like Dwarf Fortress. This write-up in Rolling Stone’s Glixel is a good overview of how it works: a hundred and forty years of town history are generated, and then the player interacts with the people in the town while James Ryan, as the background wizard, looks up relevant data and Ben Samuel uses his professional acting skills to portray the characters that the player interacts with. (Here’s a video with some snippets of the game.)
Before now, the only way to see the game in action was to be at one of the few venues that it was being presented at. This is going to be the first time that it is livestreamed.
I saw it at the SF MOMA a couple of months ago, and was one of the people encouraging them to record the game. I’m really excited that they’re making this happen, because it’s the kind of thing that I think more people should know about.
This morning, I happened to check up on what the neural network I’ve been training has been up to. It’s based the NeuralEnhance code but I’m deliberately training it with paintings instead of photos so it’ll recognize brush strokes (and maybe even introduce them if I run it on a photo.
When I started training it, the early results were like this:
There’s a strong dithered checkerboard look to that reconstruction. Here, I’ll make it larger so you can see the details:
Not the best result. That checkerboarding is a common occurrence when the sampling cells overlap. I tweaked a couple settings to deal with it better, but the effective remedy proved to be just way more training.
A little later on it was getting the hang of things, but could sometimes still fail pretty spectacularly on tricky inputs:
As you can see, it doesn’t really look much like the input. I figured that kind of input was probably always going to give it trouble.
Since I was running it on my spare computer I could forget it for a couple of weeks. That computer has a slower GPU, but more time to render. (And makes a really good space heater while it’s working on it.)
This morning, I discovered that, a few hundred generations later, it’d managed to learn how to deal with complex paint splotches like that:
Which is a pretty astonishing reconstruction.
Of course, this is still all just the training verification so far: I haven’t had time to try it out on a larger project. But the results are looking pretty promising for what I want it to be able to do.
It’s gotten pretty good at reconstructing details at different scales (because I’ve been feeding in training data at different scales). A different approach might be to give it input information about what scale the source material is at: is a given chunk a painting of an arm, or a closeup of a couple of the brushstrokes on that arm? Seems to have done pretty well without that, though.
I’m intentionally trying to train a neural net with a high degree of bias, because I want the images I resize with it to reflect that bias. Many algorithms are biased, particularly the very data-reliant neural networks. It’s like the saying about who the sucker in the poker game is: If you can’t spot the bias in the dataset, your unacknowledged biases might be reflected in it. It’s better to know how the data is biased so that you can take steps to mitigate that.
It’s also apparent how the algorithm will invent details based on how it was trained: it can’t restore the original image, it can just make its best guess.
Often that guess is really, really good. But we should remember that it is a guess, that these images are not a recording of reality in the way we usually think about photos.
Not to mention that many lost paintings survive only as imperfect photos. What would it be like if the only surviving copy of the Mona Lisa was the Face App-altered one?
I was thinking about erosion, prompted by this blogpost from “Entropic Particles“ about taking a generated terrain and adding water erosion and rivers.
Erosion is frequently a good next step to improve a generated terrain: after the geologic forces, the water cycle is probably next most important force that shapes our landscapes. The catch is that calculating a river requires knowing the shape of the entire landscape: the Mississippi drainage basin encompasses a huge swath of the continent.
If your generator is section-by-section (such as Minecraft’s) and you try to generate rivers as you go along, it’s fairly easy to end up with rivers that go in loops if you’re not careful.
Still, rivers are important enough to human habitation that they’re often worth the expense. (Try a multi-level layer-based approach if you need open-world rivers on the fly.)
Erosion isn’t just about rivers, though: it adds a history to any kind of terrain. (And for smaller scale objects, weathering is equally important; automated weathering systems are useful tools for texturing assets.)
I haven’t tried the particular algorithm described in the blog post yet, but the results certainly look promising. Using a Delaunay graph of the terrain, you calculate the flow for each node. With the tree of the fluvial network giving the volume and direction for the water, the erosion can be calculated based on the slope of the terrain.
This is all much cheaper than fully simulating the erosion. And since performance is one reason why erosion isn’t used as often as it could be, that’s a big advantage.
Of course, I’m going to keep looking for other erosion algorithms too, because as I mentioned in the last post, it is often a good idea to have multiple ways to accomplish the same goal, so you can choose the best fit for the problem at hand.
It’s a peek at the drama of making a generator, which feels very familiar to me. I especially like that it doesn’t shy away from describing the frustrations and dead ends along the way. These are a part of every generative project, but they usually get glossed over. I think it’s important to sometimes acknowledge them, especially for people who are just starting out and don’t realize how normal it is to run into frustrations like that.
The generator itself is quite interesting: though small, the eventual result is a simple but effective application of noise and shading to create convincing-looking relief maps of tropical islands.
Correction: I have been informed that the blogpost is not by the same creators as the Tiny Isles bot, though they look quite similar at first glance. Now I’m going to have to compare the actual code they used as a starting point with this blogpost and see how the results differ.
This generator, island.js by
“lebesnec“ is inspired by, not surprisingly, Amit Patel’s Voronoi-based terrain generator. That accounts for the differences that at first glance I attributed to being further along in the development cycle, because I didn’t check the dates closely enough.
The Lebesnec generator uses the Voronoi cells to quantize the map into small regions that it can then reason about. Like in Patel’s version, it actually draws the coastline before it invents the elevation.
The Plaxorite generator, in contrast, starts with a gradient heightmap, which is a bit more usual as a bottom-up approach–but note that the Lebesnec’s generator is also bottom up, just with a different data structure.
The Lebesnec generator has more features: most obviously, lakes and rivers. This can partially be attributed to being further along in development, building on Patel’s work, but it also takes advantage of the cell-based nature of the data: by having that cell graph, the generator can operate on conceptual chunks of the land, not just individual pixels.
Plaxorite will have to come up with a different approach to generating rivers, if they want to add it. This generator reasons about things on the level of continuous values (the gradient) and as a fixed grid of pixels (the rendered result). You could introduce the rivers at either stage, but the approach used and the result you’d get would be different depending on which way you went.
At least this mixup on my part was useful to illustrate some things: for example, there are many different approaches to the same goal. But different approaches will also affect the outcomes. They have different bone structures, even if they look superficially similar on the surface.
There are lots of ways to invent island shapes, and which one you choose affects both aesthetics and results, though sometimes in subtle ways.
A National Poetry Generation Month poem generated by lizadaly.
Ants and all ages are all about—active as buds are bound by black, bubbles burn by maple blackbird body, but burst before birds before building branches back.
Creatures—clearly considered—carved colors, covered curves, comparatively called cheerful, conveniences containing changing, crowding companions. Distinct, and the deeper distance of the sea which they do not describe.
Earth exhausted every egg, else entered existence with enough effort (except each early evolution), so everywhere is edible. Fight for flowers from far—for they feed. Glaciers grew in the gloomy gardens; grow to note that grave glade, that ally, but growing grasses gracefully between glared grassy green-gray.
Here, however, he had happened; here he had held her hidden hands. It is seen in its present strange way, in its considerable joy, in every picture just before and just in June between the joining season, which they judge to kill the stars, as we know that the knowledge knows a kind of evening, of keen keep in kind.
Land straight, like legs looking, many miles with more sharp mountains, and making more that the most moment may be ever found between, as being much of houses as me that the mind be made or strangers at my bright market. No nation, nor new notes, now never needed, not noticed, nor necessary near the nose of nature.
Occasionally an old olive on one of our own spring, observed only once, only over others, pressed plants perched pictures. Pale peaks pouring: the palm-trees that proved place placed performance, provided part pebbles and passes perfect; but perhaps principally preserve perpetual poets.
Quickly, quieted, quite: and the birds resemble the system of quails but if they quest, we too but so with its question— River: of recognizing rivers, referring reflecting and returning (related to recognition) rolled round right roots.
Some species spring several, some so short, strange strains. There the tall third thing! There they travel, the trees through till they too, top them.
Upward to us, used upon us, uncommonly useful unless unable under with sometimes, usually, unfortunately, it’s under a uniform united universe.
Variations of very various volumes, natural visitors, have ended from the vast valleys when we were wanting, when we were without wide wild waters.
XVII
You are the part of the great season, and you have been seen many years and from far way to your present beauty that is much in your zest, and one that then failed to cry with them over the nervous world.
Each line tries to have all the words start with the same letter of the alphabet, A through Z. It was generated with a recursive neural network trained on public domain naturalist guides and essays.
Something I like about generated poetry, when it works well, is the way the juxtaposition of unexpected imagery creates new ideas.
This is often more about the reader than about the writer: the generator doesn’t understand the kind of picture that a line like
Glaciers grew in the gloomy gardens; grow to note that grave glade, that
ally, but growing grasses gracefully between glared grassy green-gray.
implies to the reader: I see a cold spring, where the surviving ice
that shelters in shadows of a copse of trees is contrasted by the emerging grass.
On the other hand, the neural network understands something about the relationship of these words. In a similar way to how the S+7 OuLiPo formula changes the words but not the semantic structure, the neural network preserves underlying relationships between the words, relationships that it describes in its alien hundred-dimensional classification.
I’m temped to just leave this without comment. But there’s a serious point here too:
There’s no denying that many of these systems can provide real benefits to us, such as faster text entry, useful suggestion for new music to listen to, or the correct spelling for Massachusetts. However, they can also constrain us. Many of us have experienced trying to write an uncommon word, a neologism, or a profanity on a mobile device just to have it “corrected” to a more common or acceptable word. Word’s grammar-checker will underline in aggressive red grammatical constructions that are used by Nobel prize-winning authors and are completely readable if you actually read the text instead of just scanning it. These algorithms are all too happy to shave off any text that offers the reader resistance and unpredictability. And the suggestions for new books to buy you get from Amazon are rarely the truly left-field ones—the basic principle of a recommender system is to recommend things that many others also liked.
What we experience is an algorithmic enforcement of norms. These norms are derived from the (usually massive) datasets the algorithms are trained on. In order to ensure that the data sets do not encode biases, “neutral” datasets are used, such as dictionaries and Wikipedia. (Some creativity support tools, such as Sentient Sketchbook (Liapis, Yannakakis, and Togelius 2013), are not explicitly based on training on massive datasets, but the constraints and evaluation functions they encode are chosen so as to agree with “standard” content artifacts.) However, all datasets and models embody biases and norms. In the case of everyday predictive text systems, recommender systems and so on, the model embodies the biases and norms of the majority.
It is not always easy to see biases and norms when they are taken for granted and pervade your reality. Fortunately, for many of the computational assistance tools based on massive datasets there is a way to drastically highlight or foreground the biases in the dataset, namely to train the models on a completely different dataset. In this paper we explore the role of biases inherent in training data in predictive text algorithms through creating a system trained not on “neutral” text but on the works of Chuck Tingle.
In a world where recommender systems try to sell us things we already own and AI projects are trying to revive phrenology and sell it to police departments, it is worth remembering that no dataset is truly neutral.
I think it speaks to something I’ve been circling for a while, which is that I’d like to see more generators that feed into each other and interact with other systems.
Exploration games have been a fertile field for procedurally generated stuff, but as Max points out, tends to be about consumption: every time you find an interesting location, you devour it and never return. Gardening games, in contrast, are about building and recursion, revisiting the same space but in a different state.
Videogames in general tend to use space as a synecdoche for time and progress: moving to the next map in an RPG or an FPS corresponds to moving the plot forward. It’s an easy, flat structure that’s become embedded in our playing vocabulary. You enter a new area, deplete it, and move on to the next.
There are, of course, exceptions: the kinds of games that Max is talking about where the limited space but recursive interaction feel more like gardening than conquest.
I didn’t have a vocabulary for it before I read this, but I immediately recognized that it’s relevant to a question I’ve been puzzling over for a while, when it comes to certain games: Does the map look more interesting or less interesting once you’ve interacted with an area?
Some games feel quite dead if you turn around and look at where you’ve been. Others at least record your history. Some are more vibrant when you’ve finished than when you started.
A Tracery poetry project for NaPoGenMo, inspired by the Chinese geography book Shan Hai Jing.
Effective generative text is often about marrying form and content, which this does wonderfully. It reminds me of of someothertravelogue-esquegenerators, but it has its own voice.
10 miles southwest is a mountain called Mount Give-Horse. Near the top are found scattered Dry crows. On this mountain are found a great many Younger-Color trees, which look like a birch but with flowers like a daffodil. The deity of this mountain is Divine-Earth. To sacrifice to this deity, make a burnt offering of olive oil or fruit. Their shrine has a small reredos and is usually placed beside a rock. The river Younger-Petal rises here and flows west. On its banks can be found uncountably many Spring-Burning crows.
Some of the names are a bit Dwarf Fortress-y, which makes sense given their shared use of names translated literally.
270 leagues west is a mountain called Mount Breaking-Sparrow. Here
there are Sleeping-Child fowl. On its slopes are found innumerable
waningbushes. The mountain is presided over by the deity Eat-Waning. The
river Food-Ant rises here and flows west.
20 leagues northeast is a mountain called Mount Love-Bright. Around the
peak can be found a great many Turning-Day dogs. Around the peak can be
found a handful of trees that look like birches with papery leaves. The
river Love-Bitter rises here and flows south. In it live thousands of
Cruel-Bird fish.
This project by Damien Henry is an hour-long music video set to Steve Reich that was entirely generated with a neural network. Specifically, a motion-prediction technique, where it tries to predict the future from the current frame..
I admit I’m slightly jealous, since my own neural networks are still training. Though I’m going for a very different approach, and I have to admit that it was pretty ingenious to train the network with what appears to have been footage out of a train window. That gives the training data moment-to-moment consistency but continually changing data in a way that other motion prediction neural networks haven’t tried.
I think we’re rushing through the tech for neural network artistic output: a year ago this would have been impossible, a year from now the cutting edge results will look quite different. There’s already some past results that are visually interesting but you have to dig up the code to recreate them, such as the early stylenet stuff.
You could probably recreate its gradual painting with the current tech, but you’d have to tease out the individual steps.The current stuff is more robust and often better looking, but sometimes there are specific stops along the way that are unique and hard to capture with later versions. (It was also way, way slower, which is one reason why we’ve moved on.)
The specific hallucinatory look of Damien Henry’s train journey is a unique product of this exact point on the neural network development curve. Future neural networks will likely be interesting in their own ways (and faster) but won’t be exactly the same. Together with the sensitivity to the training data, every neural network is unique in its artistic potential.
We can, of course, group them in general categories. And the basic DeepDream puppyslug networks have pretty much mushed together into ten thousand bowls of oatmeal. But there’s still something magical about each moment in this artistic conversation.