

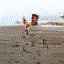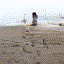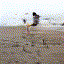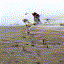






Generating Videos with Scene Dynamics
What if a computer could predict the future? Show it a still photograph, and it’ll try to guess what follows? Admittedly, these hallucinatory videos show that the computer has a long ways to go before it can produce realistic results…but it does kind of work.
The general idea behind this research is to use adversarial training to train a neural net to recognize how a scene can change. There’s two networks here: a generator network that tries to assemble a video based on massive amounts of unlabeled video, and a discriminator network that tries to guess which videos are fake.
That’s the basics. The research (by Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba) involves a lot more details, like exactly how they built their model, or how it works even better if you explicitly separate the stationary background. But the most significant part of the research is probably that they got these results by using unlabeled video as the training source, enabling them to automate more effectively and acquire massive amounts of input data via Flickr.

I admit, though, that I’m mostly posting these for the images themselves, rather than their future potential. No matter how the tech develops in the future, the transitional stage is interesting in itself: I don’t know of any other method that produces video quite like this.

While an effective future-predicting algorithm has a lot of practical uses (such as frame interpolation for film editing) I’d be interested in seeing this hallucinatory style scaled up to production resolution.

Dreamlike imagery is quite hard to approximate: film VFX gets a lot of mileage out of fluid and smoke sims, and there’s some morphing techniques, but you’d really have to go back to optical processes to find an effect like this. Tarkovsky would have found it useful for Solaris or Stalker.