
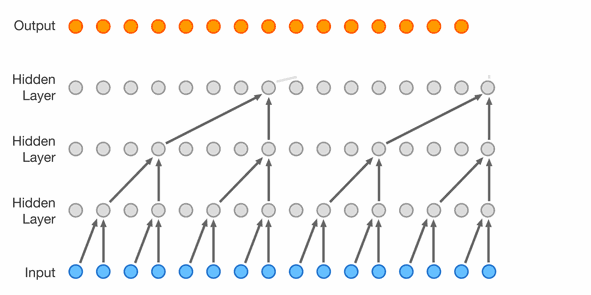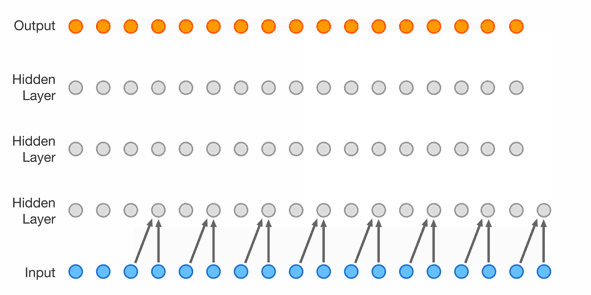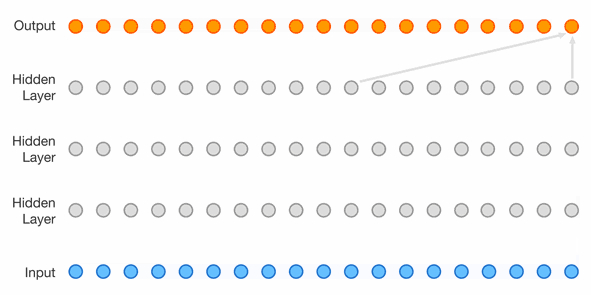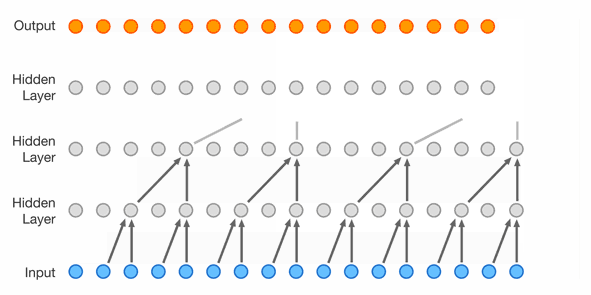

WaveNet
We’ve seen neural networks used to generate speech before, but this research project doesn’t just blow past examples out of the water: it also outperforms state-of-the-art text-to-speech approaches.
Because it operates by looking at the the audio signal directly, they also tested feeding piano music into it, generating speech without text, swapping voices, and reversing the process and using it to perform speech recognition.
The results point to a future where it will be much easier to generate speech that reflects the emotional content, or where the speech data for a large number of different-sounding NPCs can be generated from one voice actor.
https://deepmind.com/blog/wavenet-generative-model-raw-audio/